Ipl Predictor – We know that the IPL season is about to start and we all are eager to know in advance who will win the game with a lot of hype in the media about the chances of winning.
If I said we could create an app that could predict outcomes, yes! With the power of machine learning and deep learning, you can do these amazing things, and this article is all about it.
Ipl Predictor

In particular, here we’ll look at how to train a model from scratch and embed it into a web application using simple yet powerful libraries like sklearn, pandas, and Flask. In addition, some web development is also involved.
Ipl Team Win Prediction Project Using Machine Learning
The section below provides an outline and some rules to read first.
We’ll dive into each of the sections above, which are common steps performed by data science teams. This will also ensure that you learn how to approach problems with a productive mindset.
Note:- It is better to create a new environment and start working on each project in it as this will help to separate items and increase productivity.
Caption: H2 – Heading Main Section H4 – Heading – Consists of Main Bold Subsections – Subsections of Subsections Data Collection for IPL Score Predictor
Ipl 2023 Prediction Time!
Before starting the project, we need to collect information. This step can be done using the following 3 methods:
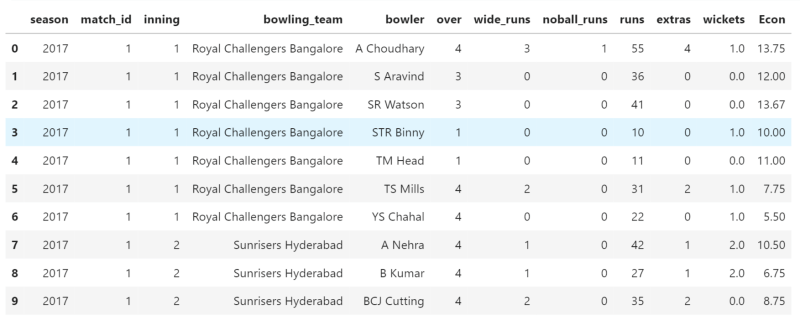
For our use case, we will use the IPL scores dataset (reference link), which has 76104 observations and 15 features:
The first thing to note here is that our dataset has certain columns that are irrelevant and increase resource consumption, so maybe we can remove them in a later step.

After a quick look at the data, let’s dig deeper into the dataset and explore some insights. This process is very important and will allow us to understand the data and plan the next steps. Fortunately, pandas provides an easy-to-use function to perform our analysis. So, let’s get started.
Get Accurate Ipl Prediction 2021
Even if we know the shape of the data (observations and features), the information can be wrong. Therefore, it is a good idea to check our data once. So let’s check it out.
In a real situation, the data we find is not the type of data we need, so we’d better check that as well.
Now that we understand the form and information, we will now check for NULL values (fields with no data – NAN). This is critical for any project because null values can change the whole story the data is telling, or even make the data worse for the use case. Let’s do the same
All we need to do is use the is_null method of the dataframe and then sum the result to get the total count for each column.
Axelerant Ipl Prediction Pro
It looks like we are lucky because there are no null (0) values in the data set. Both are of type int64 – take up a lot of memory
Just because there are no nan values doesn’t mean our data is a good representation. To get the point across, we can draw summary measures, which typically include:
1. Measures of Central Tendency – These measures allow us to understand where the bulk of the data lies and include:

2. Measures of Dispersion – These measures allow us to understand the breadth of the data and include:
Who Win Today Ipl Match Prediction
Doing each check would be cumbersome, so pandas wraps everything in a function called “describe”. Now let’s examine the summary statistics of the data.
We see that the data is almost in a similar range for all columns, so we can deduce that this is good data worth processing.
Now let’s check how each numerical feature contributes to our data set, we can do this using a pandas area plot.
Additional operations are possible. But that’s enough for now and we can move on to the next step.
Ipl Auction 2024: Predicting The Next Millionaires
With our material understood, we can now move on to cleaning it up for our use case. We’ll start by removing some columns to make the job easier.
A closer inspection of our data reveals that we have many unrelated columns such as ‘Mid’, ‘Pitch’, ‘Basters’, ‘Bowlers’, ‘Strikers’, ‘Non-Strikers’. They do not contribute to data and can be deleted to save memory space.
To remove irrelevant columns, all we need to do is build a list of irrelevant columns (cols_to_remove) and pass it to pandas’ drop method.

Tip: Here we use axis = 1 to delete by column and inplace = True to ensure the operation is performed on the same dataset.
Ipl 2023 Prediction: Today’s Match Toss Winner Predictions
We see that the column has been removed successfully as our column size has been reduced to 9
This operation is irreversible and may result in an error if performed on another drive. Filter consistent teams:
Next, we’ll filter out the teams that are still playing. This will allow us to have a core set of teams relevant to the IPL.
To do this, we’ll first find the unique teams in bat_team, build a list of them, and then filter.
Building An Ipl Score Predictor
Now we will make a list of consistent teams and store it in consistent_team for reference.
Now let’s check the results by printing the unique values again, which should return the same unique values.
Assumptions:- We can assume that “In most matches, the actual match starts after 5 rounds have passed”, so it can serve as a good starting point for our training data.

So follow our hypothesis. We will first access the overs column of the data frame (pdf) and use the >= operator to return all observations after 5 epochs.
Ipl Match Prediction Astrology
Using these types of assumptions is very common and can even produce good results as long as they meet real-world requirements, but requires domain knowledge 👍
Upon inspecting the information in the characteristics column, we discovered that the data field is an object data type and cannot be operated on.
Now, it is obvious from the information that our data takes a variety of data types, including strings, data times, and numbers. But our model requires all of this to be in numeric format, so let’s see if there’s anything we can do to make it model-friendly.
Looking closely, we can see that bat_team and bowl_team are categorical data and can be encoded as numbers (0/1). This is called “ONE HOT CODING” and can be done via the pandas get_dummy function.
Win Prediction Today Ipl Match
As can be seen, the columns were added and coded one-hot. Although it takes up more space, this is a trade-off to consider, and coding is up to the individual.
Now it’s time to split our data into (training and test sets) so we can fit it to our model.
As a general case, we split the data according to the ratio of training = 80% and testing = 20%, but here we will learn how to adapt the splitting of the problem domain.

What we’re going to do is, instead of dividing by ratio, we’re going to divide by year.
Ipl Prediction Whatsapp Number
So what I did here was to define the variable, remove the last column and filter the observations based on a condition that returns only the year value from the given column.
For tags, we only use one column (total), Panda assumes it’s an array, so we need to use values on it, otherwise it will sometimes return an error.
The breakup was successful. Also note that y_test is (2778, ) because it is a single column with 2778 observations.
The last thing we can do before closing this section is to remove the facts column from our training and test sets as it is of no use to us now as this will help free up memory space for operations subsequent.
Ipl 2023: Rcb Vs Lsg, Today Match Prediction
If you’ve come this far with me – congratulations, you’ve understood the essence of being a data scientist (yes, that’s what data scientists do!).
The only thing left now is to select a model/build for training, evaluate the results and finally save it for the last use case.
After all the effort we put in, now it’s time to choose the model architecture for our use case. This will be a function that will find a way to map our training set to training labels, allowing prediction scores given the input material.

Since we have seen that the data has mostly linear relationships (as is evident from the description), we will use a simple linear regression model for sklearn’s use case.
Pdf) Prediction Of Ipl Match Outcome Using Machine Learning Techniques
Before proceeding, we will first import the linear regression model from sklearn’s Linear_model class and instantiate the linear regression object as reg.
The job of the linear regression model is to find the line of best fit with very little error/loss
Now it’s finally time to train our model. To do this, we simply use the matching method and pass in our training set.
That’s it, we’ve trained our model and can use it to predict our test set.
Who Will Win Today’s IPL Match? Ipl 2023, Match 18: Pbks Vs GT Match Prediction
After training comes the evaluation part, which tells how our model performs on data other than the training set. If he behaves well
Ipl, stock predictor, fit predictor, cycle predictor, nclex predictor, predictor, sports predictor, ipl win predictor, future predictor, fertility predictor, hunting predictor, price predictor